Retrieval-Augmented Generation (RAG) is a powerful technique that combines information retrieval with generative AI models to improve the accuracy, relevance, and factual grounding of responses.
🔍 What is RAG?
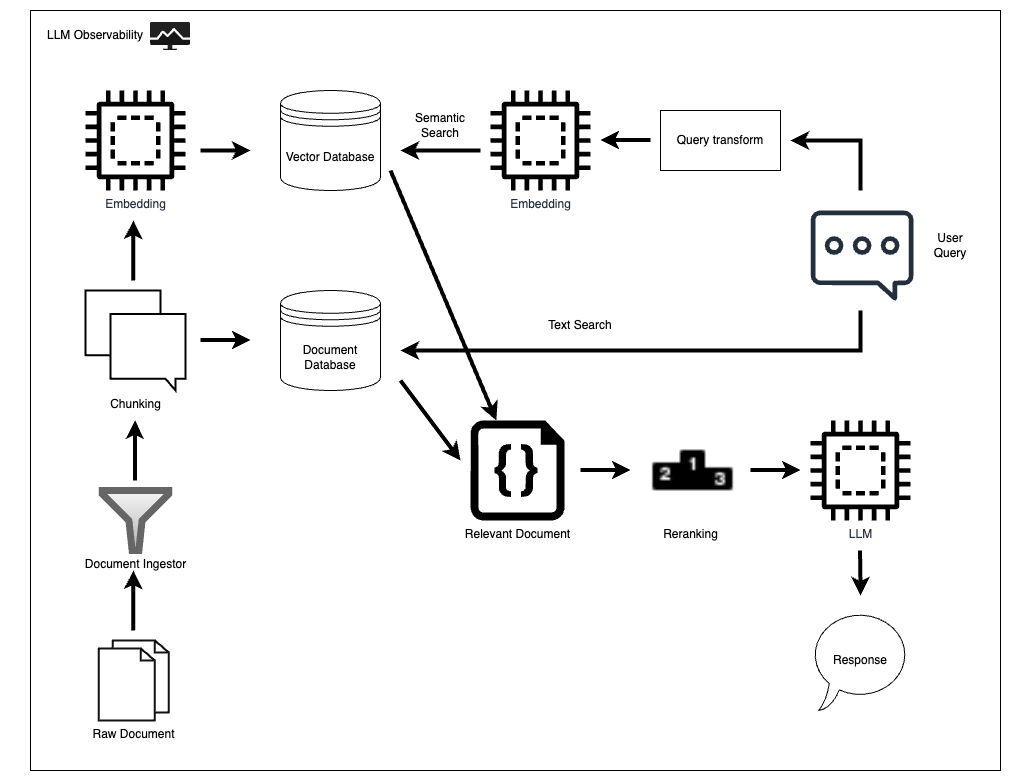
RAG is a hybrid architecture that enhances a language model (like GPT) by integrating it with a retrieval system. Instead of relying solely on the model's internal knowledge, RAG retrieves relevant documents from an external knowledge base (like a database or search index) and uses them to generate more informed and accurate responses.
⚙️ How RAG Works
- Query Input: A user provides a question or prompt.
- Document Retrieval: The system searches a corpus (e.g., Wikipedia, internal documents, vector database) for relevant documents using embeddings or keyword search.
- Context Injection: Retrieved documents are passed as context to the language model.
- Response Generation: The model generates a response based on both the query and the retrieved documents.
🧠 Benefits of RAG
- Improved Accuracy: Reduces hallucinations by grounding answers in real data.
- Dynamic Knowledge: Can access up-to-date or domain-specific information not stored in the model.
- Explainability: Responses can be traced back to source documents.
- Scalability: Works well with large corpora using vector search (e.g., FAISS, Elasticsearch, Azure Cognitive Search).
🛠️ Tools Commonly Used in RAG Systems
- Embedding Models: To convert text into vector representations (e.g., OpenAI, Hugging Face models).
- Vector Databases: FAISS, Pinecone, Weaviate, Milvus.
- Generative Models: GPT-4, LLaMA, Claude, etc.
- Frameworks: LangChain, Haystack, LlamaIndex.
📦 Example Use Cases
- Enterprise Search: Answering employee questions using internal documentation.
- Customer Support: Providing accurate responses from product manuals or FAQs.
- Legal/Medical AI: Generating insights from case law or medical literature.
- Education: Personalized tutoring using textbook content.
📊 RAG Architecture Diagram
Comments
Post a Comment